

您可以观看一段视频,了解更多有关使用特殊日期提高预测精度的信息。
在查看预测数据步骤时,您会看到所有选定技能的预测量和 AHT。 数据可能看起来不准确,而您希望看到正常值:
-
您会在某些区域看到 AHT 或交互量异常低或为 0.00。
-
您会在周二和周三看到交互量高峰,但历史数据显示周一达到高峰,而下降趋势一直持续到周五。
在这些情况下,请考虑更改历史数据。
在历史数据步骤中,查找不太符合标准的日期。 例如,由于产品促销,某一天的交互量可能过高。 这就不是一个标准的日子。 因为这种情况,预测数据将对某些技能显示不准确的交互量或 AHT。
为了提高预测的交互量和 AHT 的准确性,请将这些日子定义为特殊日期。 在特殊日期设置中,选择从未来预测排除该日期。 在预测数据步骤中就不会考虑这些日期。
当全天的预测交互量为 0 时,您将无法编辑该数量。
您可以通过查看按天 (1D) 的数据来检查全天的交易量是否为 0。 在日视图中,您可以看到一天中每个间隔的数据。
如果所有间隔的数量均为 0,这就是您无法编辑数据的原因。
为了能够编辑数量,请至少更改一个间隔。
例如,1 月 25 日预测交互量为 0。 您当前正在查看月视图 (1M)。 在这种情况下,您将无法编辑或批量编辑。
要编辑 25 日的数量:
-
转至日视图 (1D)。
-
编辑至少一个间隔。 比方说,1 月 25 日上午 8:00。 不要写 0,而是写 1 或该间隔的所需值。
-
要对全天进行更改,请返回月视图 (1M) 并进行编辑。
创建预测作业时,系统会分两个阶段计算预测数据。 首先,根据所需的技能在“预测数据”中生成数据(预测的第 3 步)。 其次,系统可以通过将工作负载分配到多个调度单位来改进预测数据。 定义人员配备参数(步骤 4)后,将重新生成数据。 这次,计算还考虑了可以处理交互的调度单位。 这确保了预测数据尽可能准确。 预测数据在人员配备中更新(步骤 5)。
基于预测作业生成计划时,预测数据基于步骤 5 中的数据。 最终的预测数据也会显示在 当日经理 的预测列中。
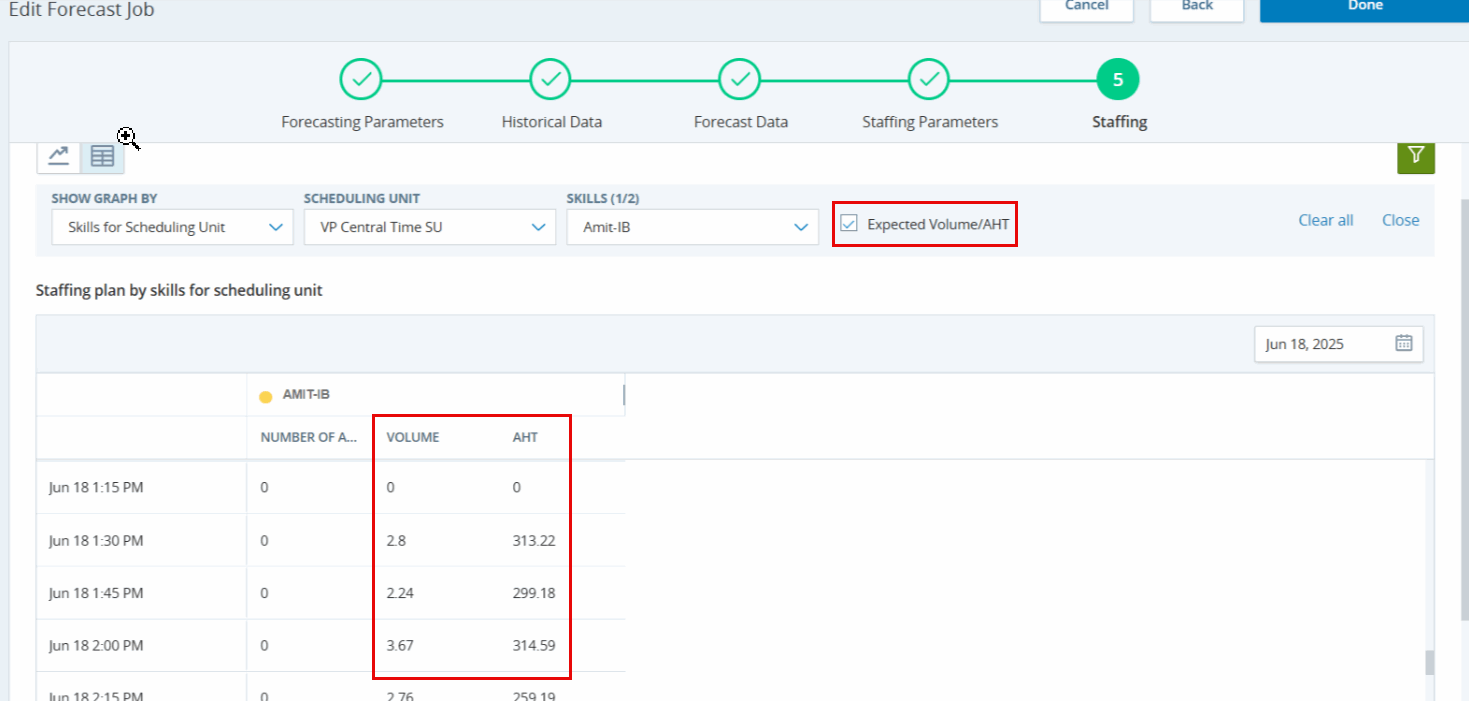
在预测过程中,(步骤 3)涉及生成原始预测,仅关注每个技能的数量和平均处理时间 (AHT),而不考虑坐席。 从(步骤 3)到(步骤 5),将发生模拟过程,将坐席要求分配给处理预测技能的每个调度单元。 然后,这些要求将转换回每个计划单位每个技能的数量。
在(步骤 5)中,如屏幕截图所示,我们可以观察从凌晨 8:00 到凌晨 8:15 间隔的数量和AHT,这表示作为模拟结果,每个调度单元每个技能要处理的预期联系数量。
假设您于 2021 年 4 月激活了 ACD。 这是开始收集历史数据的时候。 然后,您于 2022 年 11 月激活 WFM。 因为您已经收集了一年以上的历史数据,因此应该能够在生成预测时自动使用它。
然而,预测作业表明无任何历史数据(在步骤 2 中)。 要解决此问题,您需要联系技术支持。 他们会将您收集的历史数据导入到WFM中。
该系统正在按设计工作。 自动选择功能会根据过去的数据自动选择最佳预测模型。 在这种情况下,系统选择对于给定的数据来说似乎最准确的模型。 尽管它在周四产生了峰值,但这是该系统预期功能的一部分——它根据过去的结果选择了似乎是最佳选项的选项。
结果的差异来自两个模型处理数据的方式:
-
自动选择模型选择了最适合过去数据的预测方法,但它选择了每周模式(如周四的峰值)并将其延续到未来。
-
指数平滑(ES)模型对数据进行平滑处理,使其对周四的峰值不太敏感,并产生了更稳定的预测。
这两个模型给出的结果不同,因为它们旨在以不同的方式处理数据,并且每个模型都有其优势,具体取决于数据的行为。
自动选择模型正在执行其设计的目的:它选择它确定的模型,该模型将根据历史数据提供最准确的预测。 然而,在像这样的罕见情况下,该模型可能会发现不适用于未来的不寻常模式,例如周四的峰值。 客户可以使用自动选择功能,但在某些特定情况下,他们可能需要手动选择不同的模型(如指数平滑)才能获得更准确的预测。
考虑到客户是高级许可证持有者,当他们认为自动选择的模型未提供最佳结果时,他们可以选择手动选择预测模型。 这种灵活性使他们能够根据自己的特定需求选择最合适的型号。
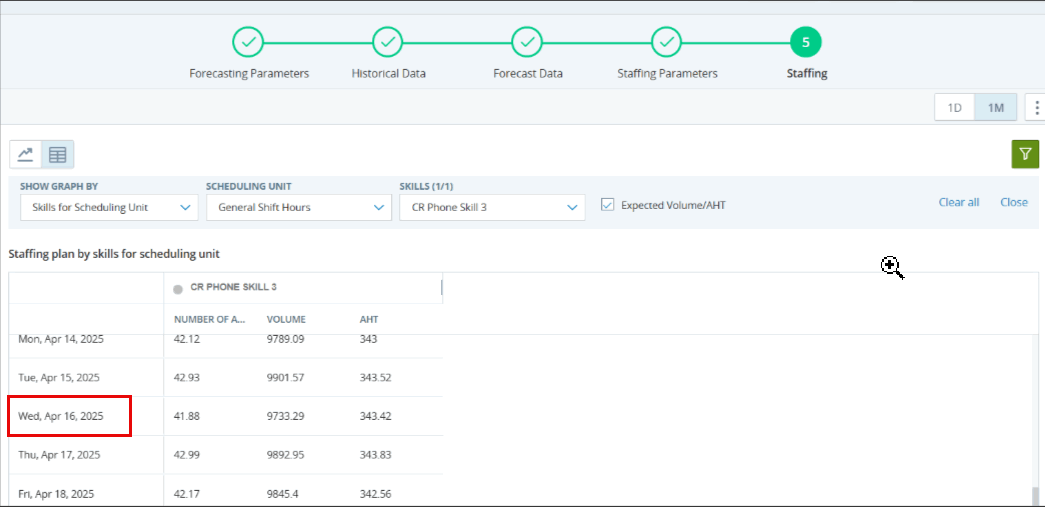
在以下工作的人员配置屏幕中,让我们考虑 1 月 15 日技能“联络中心”的一个间隔,如下图所示:
在上面的示例中,我们可以看到技能 Contact Center的交易量为 4.71,AHT 为 100.43。 这意味着在 900 秒 (15 分钟) 的间隔内,所有呼叫都将由 AHT 为 100.43 的单个代理处理。 如果我们在计算中使用确切的数字,则 0.53 的人员配备要求是正确的,因为调度单元中有 67 个座席。
更改服务级别不会影响人员配备,因为我们有足够的座席来处理呼叫。 当我们在人员配备生成期间查看调度单元中的 Contact Center 配置时,我们看到总共有 67 个座席可用于处理所选技能的呼叫。 因此,在生成人员配备要求时,如果每个间隔中有足够的座席可用于处理预测的交互,则不会考虑 SLA 平均应答速度。
但是,如果在给定间隔内没有足够的座席可用于管理预测的呼叫,则使用 SLA 平均应答速度 指标来确定满足服务级别目标所需的座席数量。 此原则适用于此角色的所有间隔、技能和计划单位。 考虑到低容量和 AHT,以及足够的可用座席数量,人员配备数量保持不变,因为有足够的座席来始终满足 100% 的 SLA,因此 平均应答速度 实际上计算为零。
根据历史数据请求,我们验证 ACD 技能是入站还是出站,以及 WEM 技能方向是入站还是出站。 如果它们不匹配,则历史页面上会显示一条消息,指示方向不匹配。
错误信息:
-
WEM 技能方向与 ACD 不匹配。 将这些 WEM 技能与 ACD:客户支持 OB 保持一致。
可能的原因:
-
案例 1: WEM 技能是入站的,但映射到它的 ACD 技能是出站的。
-
案例 2: WEM 和 ACD 技能都是出站的,但上传的历史数据被标记为入站。
-
案例 3: WEM 和 ACD 技能都是入站的,但由于在上传过程中将出站标志设置为 True,因此上传的历史数据被标记为出站。
-
案例 4: ACD技能被删除并重新创建。 在这种情况下,WEM 技能和 ACD 技能之间的原始映射将被丢失。
解决方法:
-
确保上传的历史数据与 ACD 技能配置一致。 如果ACD技能定义为出站,请在上传过程中将 isOutboundFlag 设置为 True。 否则,如果ACD技能定义为入站,请将isOutboundFlag设置为False。
-
如果一个 ACD 技能被删除并重新创建,请将 WEM 技能重新映射到新创建的 ACD 技能。
-
如果 ACD 技能映射为入站,但关联的WEM技能的分配给渠道设置为 拨号器,则必须删除该WEM技能。 创建入站类型的新 WEM 技能,并将其与相应的入站 ACD 技能关联。
-
从重新加载历史数据WFM> Forecasting >ACD历史数据并确保至少有 13 周的历史数据可用于准确预测。
在CXone Mpower WFM中,目标平均应答速度(平均应答速度)是人员配置计算中使用的可选参数。
-
您可以将目标平均应答速度定义为人员配置参数的一部分,但这不是强制性的。
-
如果未定义目标平均应答速度,则人员配置流程仍将使用其他输入(例如服务等级目标)运行,以生成人员配置建议。
生成人员配置后,系统会运行模拟,模拟联系人在真实世界的 ACD 中如何到达、排队和接听。 根据此模拟,系统确定:
-
满足定义目标(服务等级和/或平均应答速度)所需的代理数量。
-
平均实际等待时间客户在计算出的人员配置中会体验到。
此实际等待时间将成为日内显示的预测平均应答速度。
-
如果定义了目标平均应答速度,则预测平均应答速度将反映基于该目标的模拟结果。
-
如果未定义目标平均应答速度,则预测的平均应答速度仍会作为基于服务等级的模拟的一部分自动计算。
无论是否配置了目标平均应答速度,日内始终根据人员配置模拟显示预测的平均应答速度。
当为同一WEM技能定义了多个服务目标(例如 服务等级、目标平均应答速度 和 最大占用)时,CXone Mpower WFM 会在人员配置模拟期间同时评估所有目标。
-
系统计算满足每个单独目标所需的代理数量。
-
然后,它从中选择最高的人员配置需求。
例如:
-
服务等级目标需要 20 个座席
-
目标平均应答速度需要 22 个代理
-
最大占用人数需要 18 名代理
-
最终人员配置要求 = 22 名代理(三个代理中的最多一个)
-
这种方法可确保人员配置建议满足所有定义的服务目标,而不仅仅是一个。
当为同一 WEM 技能定义多个服务目标时,系统始终为最严格(最大)的要求配备人员,以确保满足所有目标。
通常不建议为同一 WEM 技能定义多个服务目标。 每个目标都以不同的方式推动人员配置,并可能引入相互冲突的制约因素。 例如,
-
服务等级和目标平均应答速度旨在减少客户等待时间。
-
最大占用限制座席利用率,这可能与 SL 和平均应答速度的目标相冲突。
尽管如此,CXone Mpower WFM提供了在需要时支持此类方案的灵活性。 人员编制需求计算器评估多个选定目标(无论是在人员编制配置文件中定义还是直接在预测作业中定义),并生成同时满足这些目标的人员配置建议。
用户有责任确保所选目标一致且不冲突。 激活多个目标会增加人员配置解决方案的限制性,这可能导致人员过剩或不可行的时间表。
预测算法使用不同的方法根据可用的历史数据量计算 AHT:
如果可用的历史数据少于 2 年:
-
该算法使用移动加权平均来估计 AHT。
-
此计算在间隔级别执行,将权重应用于每个时间间隔(例如,15 分钟或 30 分钟块)内的最近数据点。
如果有超过 2 年的历史数据可用:
-
该算法评估多个候选模型,并选择具有最低平均绝对误差 (MAE) 的模型。
-
此模型选择也应用于区间级别,允许每个区间根据其历史 AHT 行为使用最佳拟合模型。
总结:
-
< 2 年数据:移动加权平均→应用于区间水平。
-
≥ 2 年数据: 使用 MAE 选择的最佳拟合模型→应用于区间水平。